Quantitative developers are pivotal in leveraging data to make informed investment decisions. Among the array of analytical tools available, decision trees are a powerful, interpretable, and versatile method for solving financial problems. Their ability to model decisions based on structured data and clearly define pathways to outcomes makes them indispensable in quantitative analysis.
What are decision trees?
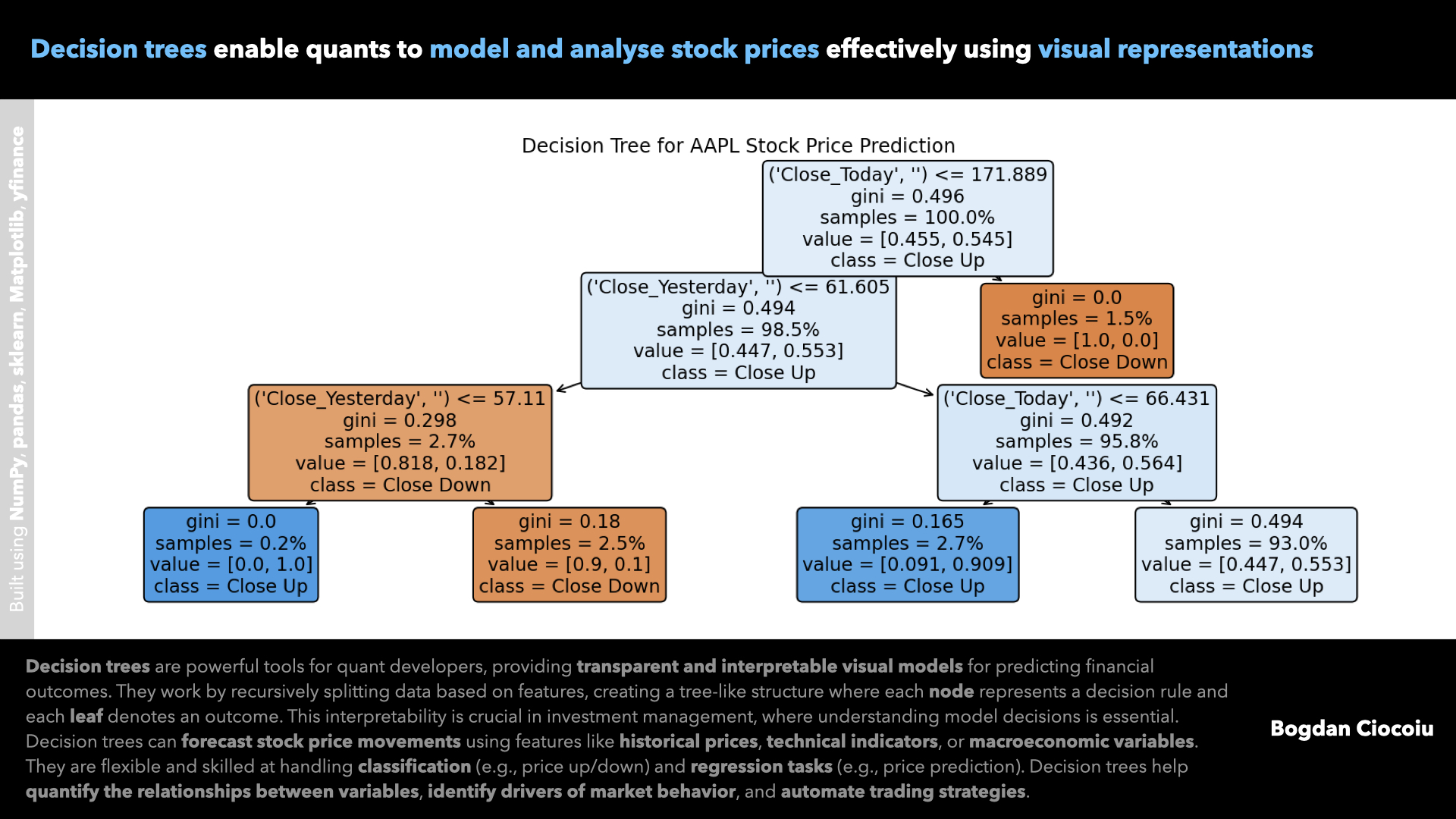
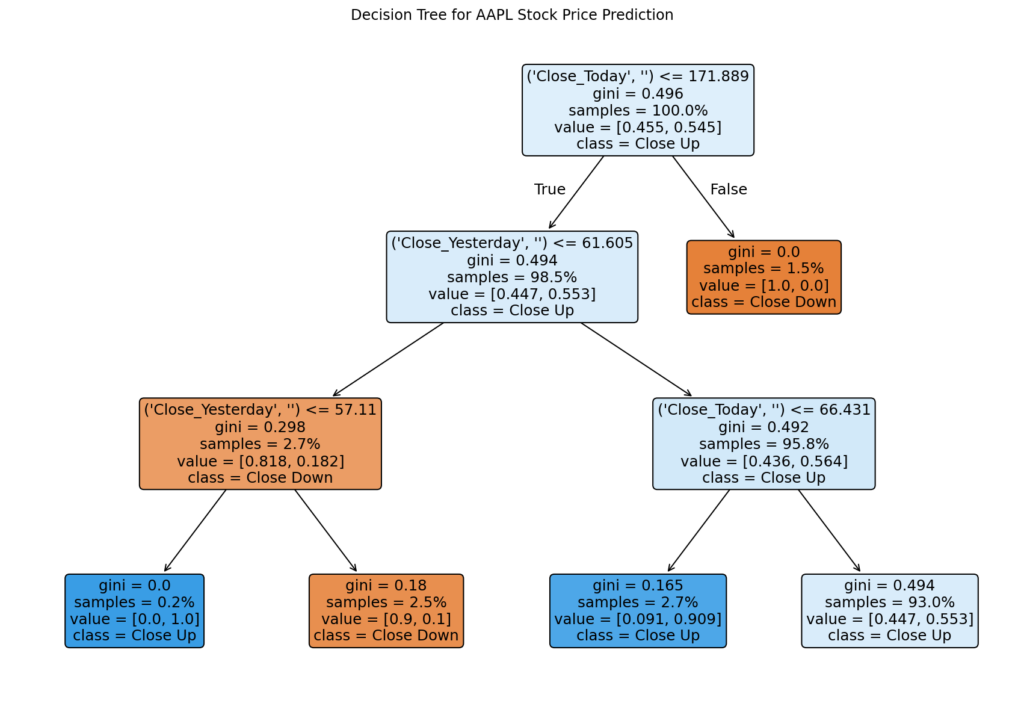
Decision trees are a supervised machine learning algorithm for classification and regression tasks. They divide a dataset into branches, following a hierarchical structure of decisions based on feature values. Each split is guided by a metric, such as Gini impurity or information gain, to ensure the most informative questions are asked at each stage. The result is a tree-like structure where leaves represent outcomes and nodes define decision criteria.
Key advantages for quantitative developers
- Decision trees are highly interpretable, making them ideal for finance, where clarity is essential. Developers and stakeholders can easily trace the decision-making process and understand which variables drove specific outcomes. This transparency builds trust in models used for investment strategies and risk management.
- Decision trees work effectively for classification (e.g., predicting whether a stock will close higher or lower) and regression tasks (e.g., forecasting stock prices). Their flexibility allows developers to apply them across various financial use cases, from equity analysis to credit scoring.
- Decision trees rank the importance of input features, highlighting which variables most influence the outcome. This insight is invaluable for quantitative developers who want to optimise models and understand market behaviour. For example, in stock prediction, a tree might reveal that volatility has a higher impact than volume.
- Financial data often exhibits nonlinear relationships, which can be challenging for traditional linear models. Decision trees naturally capture complex patterns without requiring explicit feature engineering, making them practical for modelling financial market dynamics.
- Python libraries like Scikit-learn provide robust implementations of decision trees, enabling seamless integration into existing quantitative workflows. With just a few lines of code, developers can create, train, and evaluate decision tree models.

Applications in finance
- Stock price prediction
- Risk Management
- Algorithmic Trading
- Credit Scoring
- Fraud Detection
Challenges and solutions
Despite their strengths, decision trees are prone to overfitting, especially with deep trees. Overfitting can lead to poor generalisation of unseen data. To address this, developers can:
- Prune trees to limit their depth.
- Use ensemble methods like Random Forests and Gradient Boosting, which combine multiple trees to improve accuracy and robustness.
Essential for quant developers
Decision trees simplify the complexity of financial data, offering a structured approach to uncovering patterns and making predictions. Their ability to provide interpretable results, handle nonlinear relationships, and integrate seamlessly with Python’s data science ecosystem makes them a cornerstone for quantitative analysis.
Leave a Reply
You must be logged in to post a comment.