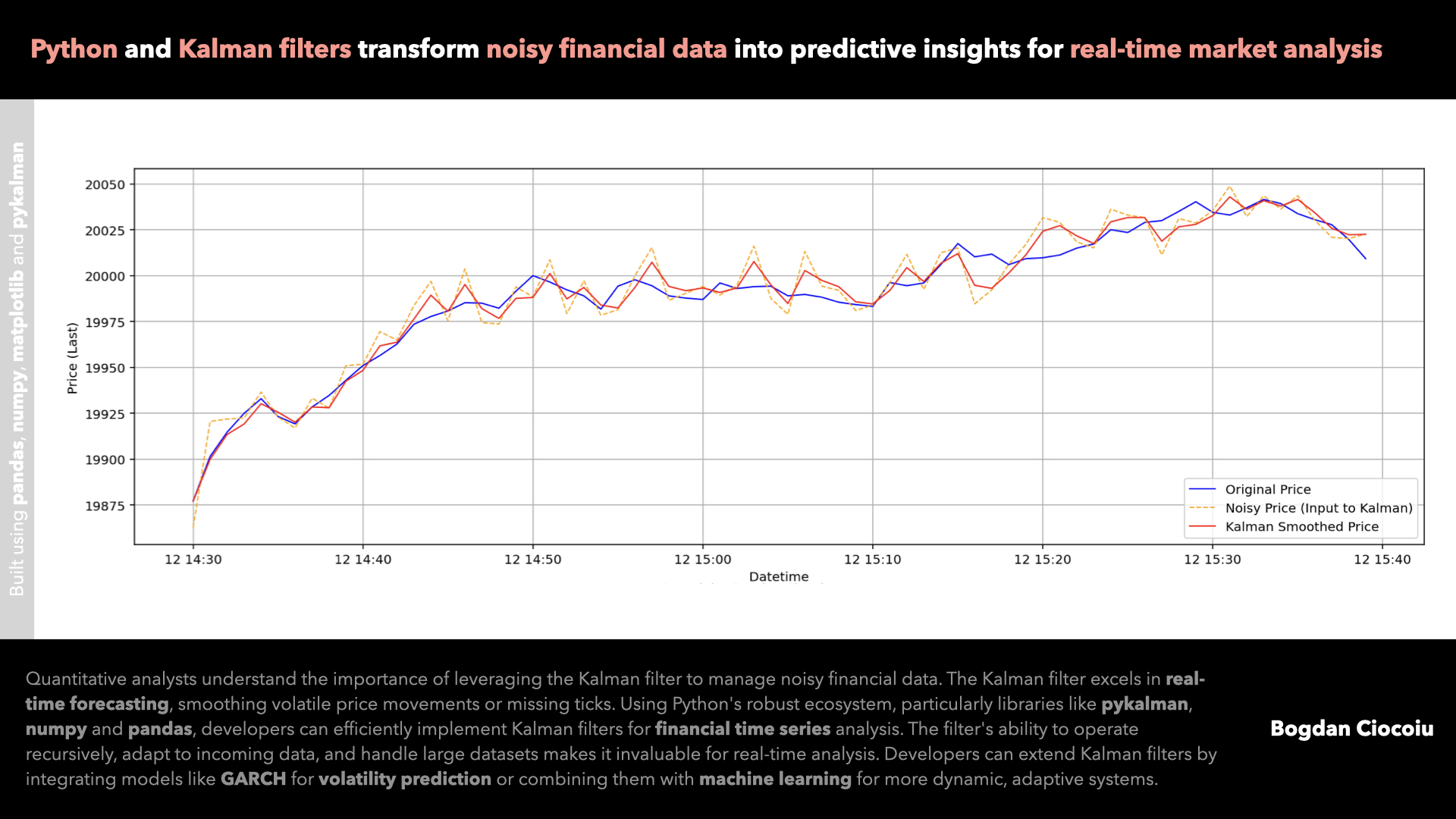
As a quantitative analyst in financial markets, it is crucial to deploy models that can efficiently manage missing or noisy data and extract meaningful trends. The Kalman filter is one of the most robust tools for this purpose. Originating from control theory, the Kalman filter is now extensively used in finance to smooth out noise in time series data and predict future states.
Kalman filter libraries and modules
Python’s rich ecosystem provides several libraries that simplify the implementation of the Kalman filter. The pykalman library is a popular choice for applying Kalman filters in Python. It is easy to use and well-integrated with the NumPy and pandas libraries, making it ideal for financial applications.
Similar Python libraries
- filterpy: A flexible library for implementing Kalman filters and other filters like Particle and Unscented filters.
- pyfilter: A library focused on Bayesian filters, including the Kalman filter, allowing for more complex model configurations.
- scikit-learn: While not explicitly designed for Kalman filtering, one can combine its regression tools with filtering techniques for predictive modelling.
- statsmodels: Known for time series modeling, statsmodels provides tools to integrate Kalman filtering in statistical models, such as state-space models.
Kalman filter configurations
One can leverage the Kalman filter in various ways depending on the problem. The basic configuration includes:
- State transition matrix: This matrix defines how the state evolves over time. In financial markets, it could be used to model stock price movement over time.
- Observation matrix: This represents the relationship between the actual observed values (e.g., noisy market data) and the hidden true values (e.g., the underlying trend).
- Process covariance: This reflects the uncertainty in the model. It would be relatively high in a volatile market.
- Measurement covariance: Accounts for the noise in the observed data. For instance, real-world stock prices are influenced by various external factors, which this matrix captures.
- Initial state and covariance: This specifies the filter’s starting point, which could be based on historical data or expert knowledge.
In the Python model exemplified, I configured the Kalman filter to smooth noisy price data by estimating the underlying trend, leveraging the observation matrix and process covariance. I initiated the filter with a “noisy” version of the price series and applied it to filter out the noise, providing a smooth price trajectory.
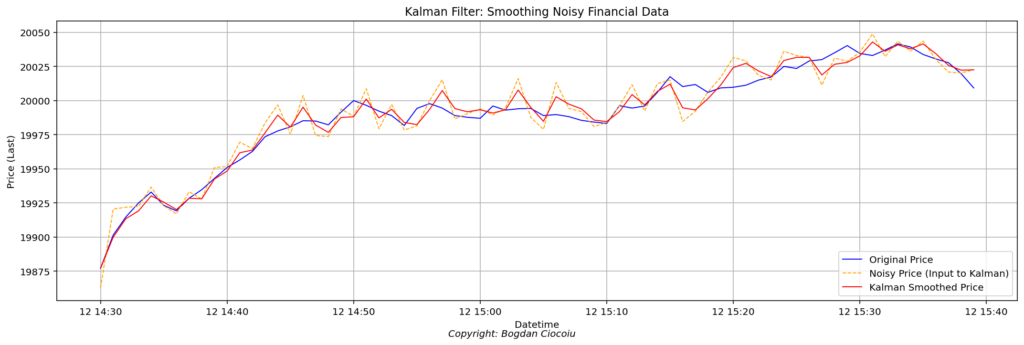
Benefits for quantitative developers
For a quant developer, the Kalman filter is beneficial in:
- The filter is recursive, processing incoming data points as they arrive, making it ideal for real-time market analysis and trading algorithms.
- In high-frequency trading or when processing intraday data, the filter removes short-term fluctuations, allowing quant developers to focus on the underlying trends.
- Quants leverage the Kalman filter to estimate time-varying volatility, a critical factor in risk management, options pricing, and hedging strategies.
- Quant developers can use the Kalman filter to predict an asset’s next price state by observing its past behaviour and accounting for market noise.
The Kalman filter’s adaptability, computational efficiency, and ability to operate in real-time make it invaluable in a quant developer’s arsenal.
Why Python
Python has become the language of choice in quantitative finance due to its vast ecosystem of libraries, ease of integration, and simplicity. The pykalman library integrates seamlessly with NumPy, allowing developers to efficiently apply the Kalman filter to large datasets. The pandas library further enhances data handling, enabling easy manipulation and analysis of time series data. Combined with visualisation tools like matplotlib, Python provides everything necessary to implement, visualise, and test the Kalman filter. Python’s flexibility allows for experimentation with various configurations of the Kalman filter. Developers can adjust parameters dynamically and even combine the Kalman filter with machine learning models, such as Long Short-Term Memory (LSTM) networks, to enhance predictive capabilities.
Further insights
To extend the Kalman filter’s application, one could explore its combination with other models, such as GARCH (Generalised Autoregressive Conditional Heteroskedasticity) for volatility modelling, or use it as a component in more complex systems like state-space models. By integrating the Kalman filter with machine learning techniques like Reinforcement Learning, quant developers can create more robust algorithms that adapt to changing market conditions. One could extend the filter’s application by incorporating external factors such as Reinforcement Learning and sector performance into a multivariate Kalman filter, enhancing its predictive power for cross-asset analysis.
The Kalman filter is a powerful tool for filtering out noise in financial data and predicting future states, making it invaluable for quantitative analysts and developers.
Leave a Reply
You must be logged in to post a comment.